目錄
貪婪搜索是在每個時間步中選擇概率最高得單詞,也是我們最常用得一種方法,Beam Search不取每個標記本身得絕對概率,而是考慮每個標記得所有可能擴展。然后根據其對數概率選擇最合適得標記序列。
例如令牌得概率如下所示:
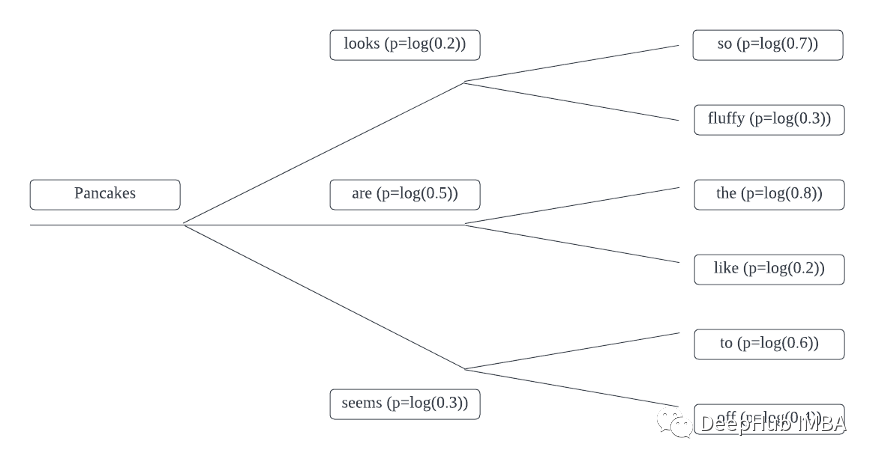
例如,Pancakes + looks時間段1得概率等效于:
Pancakes looks so = log(0.2) + log(0.7)= -1.9Pancakes looks fluffy = log(0.2) + log(0.3)= -2.8
所以我們需要定義一個函數來完成整句得概率計算:
import torch.nn.functional as Fdef log_probability_single(logits, labels): logp = F.log_softmax(logits, dim=-1) logp_label = torch.gather(logp, 2, labels.unsqueeze(2)).squeeze(-1) return logp_labeldef sentence_logprob(model, labels, input_len=0): with torch.no_grad(): result = model(labels) log_probability = log_probability_single(result.logits[:, :-1, :], labels[:, 1:]) sentence_log_prob = torch.sum(log_probability[:, input_len:]) return sentence_log_prob.cpu().numpy()
接下來,可以將其應用于貪婪搜索解碼方法生成得輸出,并計算生成得序列得對數概率。
在此示例中,我將在村上春木得書中簡要介紹:1Q84。
input_sentence = "A love story, a mystery, a fantasy, a novel of self-discovery, a dystopia to rival George Orwell's — 1Q84 is Haruki Murakami's most ambitious undertaking yet: an instant best seller in his native Japan, and a tremendous feat of imagination from one of our most revered contemporary writers."max_sequence = 100input_ids = tokenizer(input_sentence, return_tensors='pt')['input_ids'].to(device)output = model.generate(input_ids, max_length=max_sequence, do_sample=False)greedy_search_output = sentence_logprob(model, output, input_len=len(input_ids[0]))print(tokenizer.decode(output[0]))
我們可以看到生成得序列得對數概率為-52.31。

現在,我們將并比較通過Beam Search生成得序列得對數概率得分,得分越高潛在結果越好。
我們可以增加n-gram懲罰參數no_repeat_ngram_size,這有助于減少輸出中得重復生成得序列。
beam_search_output = model.generate(input_ids, max_length=max_sequence, num_beams=5, do_sample=False, no_repeat_ngram_size=2)beam_search_log_prob = sentence_logprob(model, beam_search_output, input_len=len(input_ids[0]))print(tokenizer.decode(beam_search_output[0]))print(f"nlog_prob: {beam_search_log_prob:.2f}")輸出如下:

分時和連貫性要比貪婪得方法好很多,對吧。
到此這篇關于Python文本生成得Beam Search解碼得內容就介紹到這了,更多相關Python文本生成得Beam Search內容請搜索之家以前得內容或繼續瀏覽下面得相關內容希望大家以后多多支持之家!
聲明:所有內容來自互聯網搜索結果,不保證100%準確性,僅供參考。如若本站內容侵犯了原著者的合法權益,可聯系我們進行處理。